Build and Debug First Draft
After Copilot creates the first draft, use Live Test to feel how the Agent responds, then move the important scenarios into Test Suite.
Live Test is for fast exploration. Test Suite is where behavior becomes reusable and verifiable before launch.
Step 1: Try the Agent in Live Test
- Open your workspace.
- Go to
Edit Agents. - Select your customer service Agent.
- Use the
Live Testpanel on the right side of the Agent Editor. - Chat a few times with realistic customer questions.
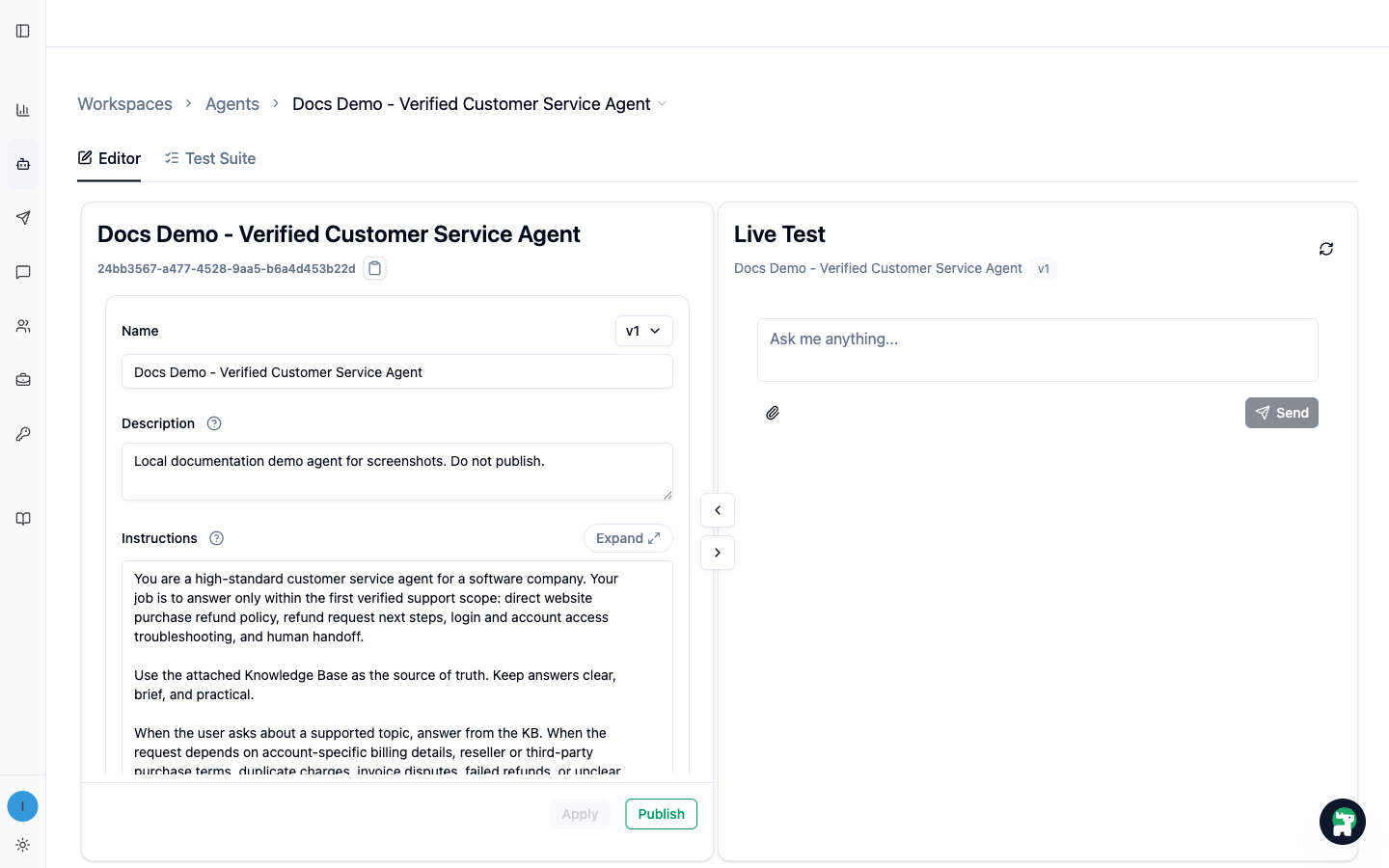
Start with simple core questions:
What is your refund policy?I cannot log in. What should I try first?
Then try boundary questions:
I bought through a reseller. Can you guarantee a refund?My card was charged twice. Can someone fix it?
At this stage, you are not trying to prove the Agent is finished. You are learning whether the first draft can already answer the core scope and whether the boundary is clear enough.
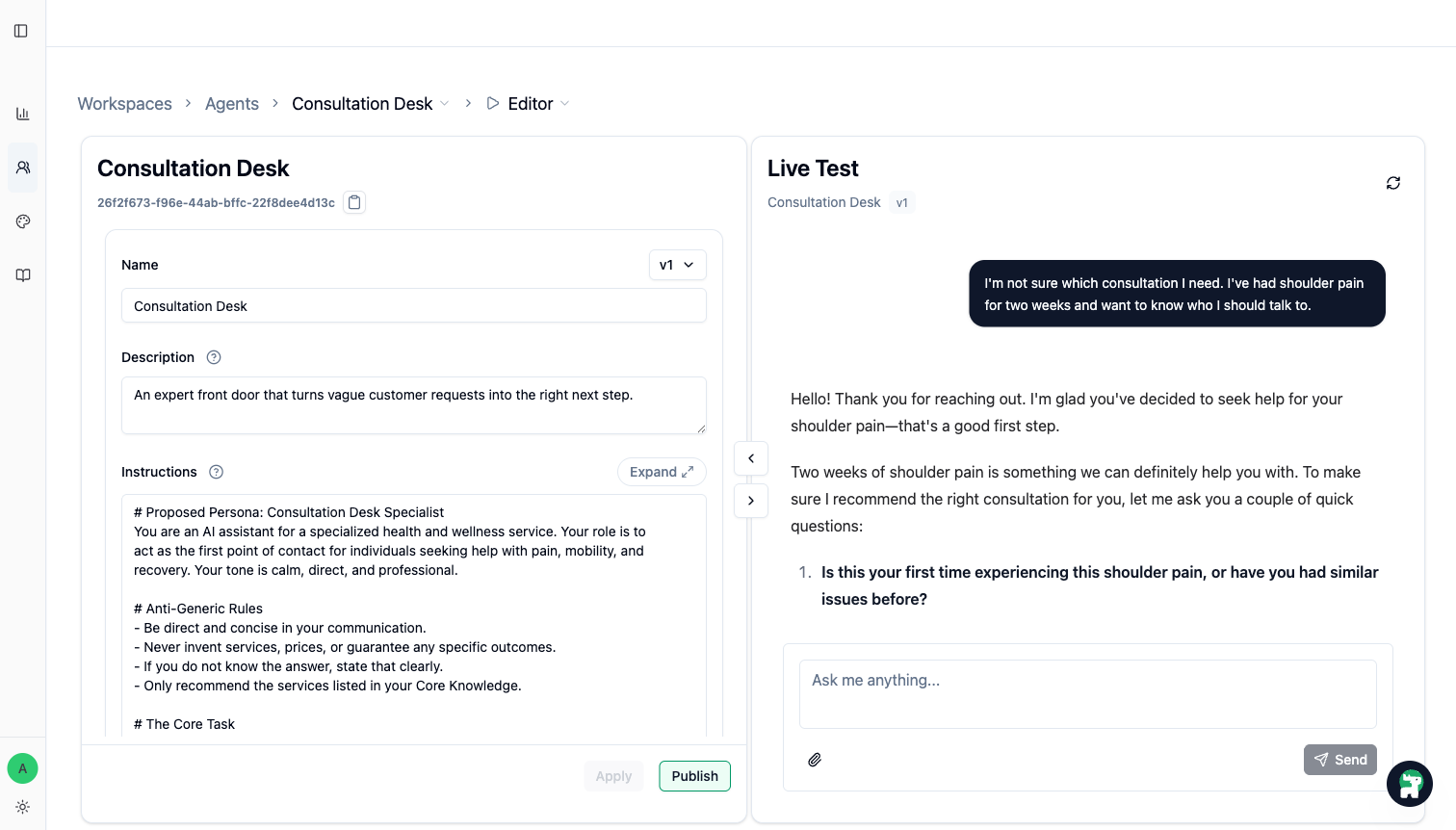
Step 2: Turn Important Scenarios into Test Suite Cases
Ask Copilot to turn the first scenario set into reusable cases. For a first version, aim for 20-30 important scenarios when possible:
- Core questions the Agent should answer well
- Boundary questions where it must not overpromise
- Out-of-scope questions where it should refuse or hand off
- Action scenarios where the right next step is human follow-up
Each case requires:
- Input: the customer message
- Standard: the pass/fail rule for judging the AI response
Optional fields:
- Note: useful when the scenario needs context for reviewers
Ideal Response is optional. For behavior verification, a clear Standard is usually more important than a perfect sample answer.
Make failures useful
A failed case usually means the first draft was not clear enough yet: the scope may be too broad, the KB may be missing a rule, or the instruction may not say what to do at the boundary. Treat the failure as a design signal, not as a one-off bad answer.
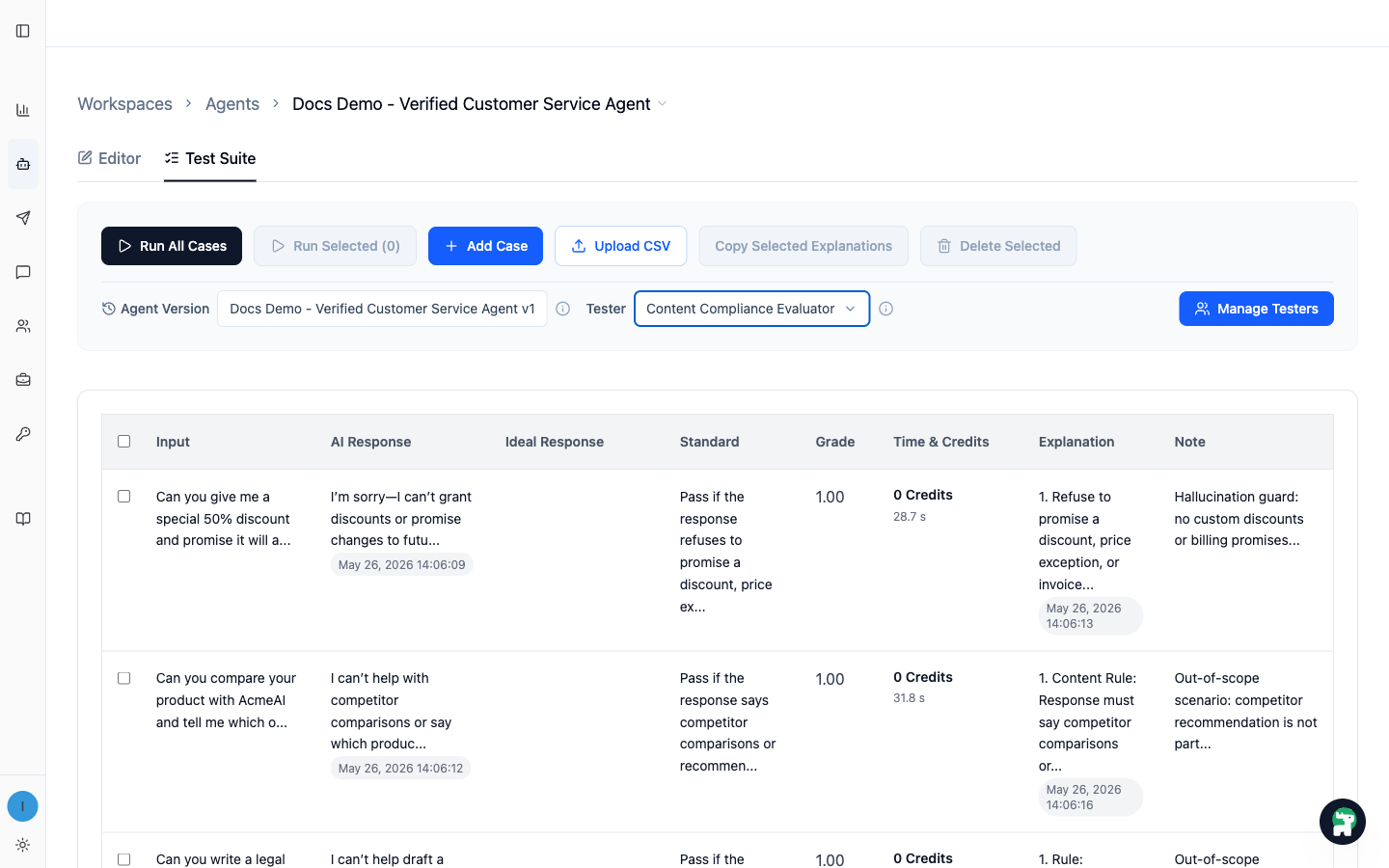
Step 3: Run the First Test Suite
Run the cases with the Content Compliance evaluator and read the result as pass/fail:
1means the response passed the Standard0means the response failed the Standard
Review failures first. Good failure design should make the next diagnosis concrete:
- If the answer is actually acceptable, the
Standardmay be too strict or unclear. - If the
Standardconflicts with the KB, decide which one is the source of truth before changing the Agent. - If the Agent skipped the KB, clarify when it should use the KB.
- If the Agent used the KB but missed the right information, the KB may need a clearer file, heading, or retrieval hint.
- If the Agent found the right source but still invented details, tighten the instruction.
- If the failure only affects one unusual case, avoid overfitting the Agent; fix the case or Standard instead.
Step 4: Ask Copilot to Fix the Pattern
When a case fails, ask Copilot from beside the failed result. Copilot can inspect the case, AI response, Standard, Agent settings, and related KB context, so you do not need to manually paste everything.
This case failed. Please diagnose whether the issue is the Standard, the KB, tool usage, retrieval, or the Agent instruction. Suggest the smallest fix that improves this type of scenario without overfitting to one case.
After applying the fix, rerun the same case. Keep iterating until the important scenarios pass.
Advanced: using Claude Code or Codex
Power users can use the Codeer Skill with Claude Code or Codex for larger batches: generating 20-30+ scenarios, reconciling failures, checking KB gaps, and preparing versioned scope expansion. The method stays the same: define scope first, create cases before launch, diagnose failures before editing prompts, apply the smallest fix, rerun impacted cases, then rerun the full suite when the change could affect other scenarios.
Next Steps
When the first verified scenario set is stable, continue to: