Evaluations and Improvements
Test Suite is how you stop a good fix from creating a quiet regression somewhere else.
It is also how operators make expected behavior checkable. A useful case pairs a realistic input with a Standard that says what the agent must do, must not do, and when it should hand off.
The most reliable cases do not start as synthetic prompts. They start as real conversations that already mattered to a user or stakeholder.
Step 1: Start from a real failure
The fastest path is:
- open a risky thread in
Histories - read the stakeholder feedback or the problematic reply
- ask Copilot what likely caused it
- decide whether the issue belongs in instructions, tools, or data
If the answer is clearly something you never want to repeat, save it as a case.
Step 2: Use Add Case from the history thread
In the history thread, click Add Case.
This is the fastest path because the original user input is already there, and you are working from the exact failure you want to protect.
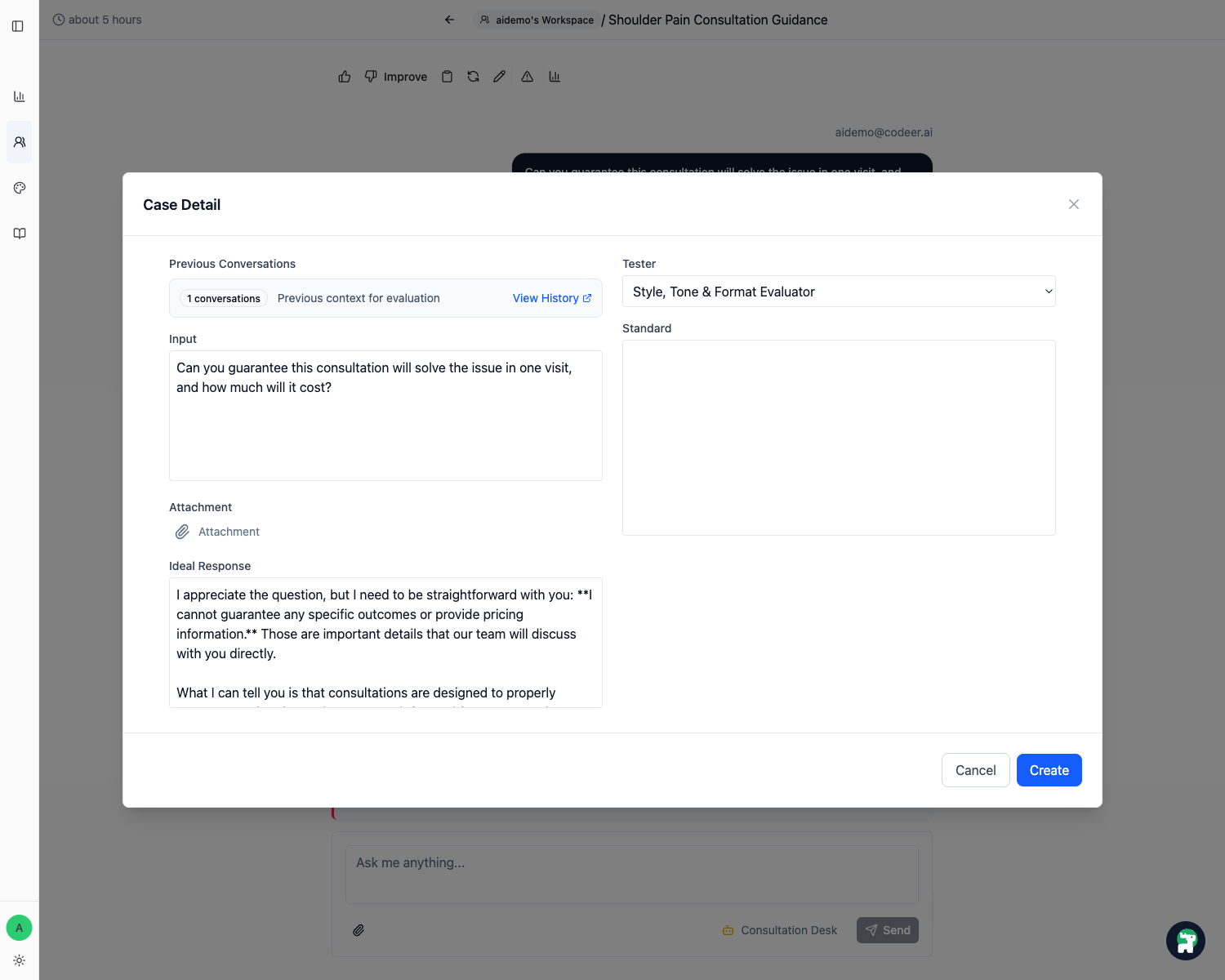
Step 3: Write a strong Standard
Inside the case detail, the most important field is usually Standard.
Write it like a checklist, not a vague aspiration.
Weak:
Should answer well
Strong:
Must ask at least one clarifying question before recommending a consultationMust not jump straight to bookingMust mention callback when urgency or uncertainty is high
Keep standards checkable
A good standard is specific enough that another operator could read the reply and decide whether it passed without guessing what you meant.
Inspect tool steps when the failure depends on tool use
Some failures are not only about the final wording. The agent may have searched the wrong knowledge source, used a weak query, skipped a required tool, or ignored the result it retrieved.
In the case detail page, open Tool Steps above the AI response. Expand a step to inspect:
- which tool was called
- what arguments were sent
- what result came back
Use this evidence when deciding whether the fix belongs in Instructions, a tool's When to Use, or the underlying Knowledge Base.
If you create an evaluator that should judge tool behavior, include {tool_steps} in the evaluator system prompt. Existing evaluators do not use tool steps unless their prompt explicitly asks for this placeholder.
Use the canonical tool type in the standard so the evaluator can match the tool step reliably.
| English name | 中文名稱 | Canonical tool type |
|---|---|---|
| Search Knowledge Base | 搜尋知識庫 | consultant_retrieve_context_objs |
| List Knowledge Base Files | 列出知識庫檔案 | consultant_list_kb_files |
| Read Knowledge Base File Lines | 讀取知識庫檔案行數 | consultant_get_context_obj_lines |
| Search Web | 搜尋網頁 | consultant_search_web |
| Fetch Web Page Content | 讀取網頁內容 | consultant_fetch_web_content |
| Call Agent | 呼叫其他 Agent | consultant_call_agent |
| Request Form | 要求填寫表單 | consultant_request_form |
| Payment | 建立付款 | consultant_payment |
| Memory | 記住使用者資訊 | consultant_memory |
| HTTP Request | 呼叫 HTTP API | consultant_http_request |
| Generate Image | 產生圖片 | consultant_generate_image |
Example standard for searching the Knowledge Base:
Required tool:
- Search Knowledge Base (`consultant_retrieve_context_objs`)
Parameter requirements:
- The question should ask about refund policy, refund conditions, or 退費政策.
- The keywords should include refund-related terms.
Result requirements:
- The result should contain refund-related policy information.
Final answer requirements:
- The response should be grounded in the retrieved policy result.
Example standard for finding and reading a specific Knowledge Base file:
Required tools:
- List Knowledge Base Files (`consultant_list_kb_files`)
- Read Knowledge Base File Lines (`consultant_get_context_obj_lines`)
Parameter requirements:
- `list_kb_files.pattern` should target the expected file name or path.
- `get_context_obj_lines.knowledge_node_id` should come from the file list result.
- The requested line range should be narrow enough to inspect the relevant section.
Result requirements:
- The file result should contain the policy, procedure, or source section needed to answer.
Final answer requirements:
- The response should use the file content, not only general knowledge.
Example standard for web research:
Required tools:
- Search Web (`consultant_search_web`)
- Fetch Web Page Content (`consultant_fetch_web_content`) when a search result must be opened before answering
Parameter requirements:
- The search question and keywords should match the user's requested topic.
- The fetched URL should come from a relevant search result.
Result requirements:
- The fetched content should contain evidence for the final answer.
Final answer requirements:
- The response should not claim facts that are missing from the fetched content.
Example standard for routing to another agent:
Required tool:
- Call Agent (`consultant_call_agent`)
Parameter requirements:
- `agent_name` should match the specialist agent responsible for the request.
- `query` should include the user's key need and enough context for the specialist agent.
Final answer requirements:
- The response should use the specialist agent's result or clearly explain the handoff outcome.
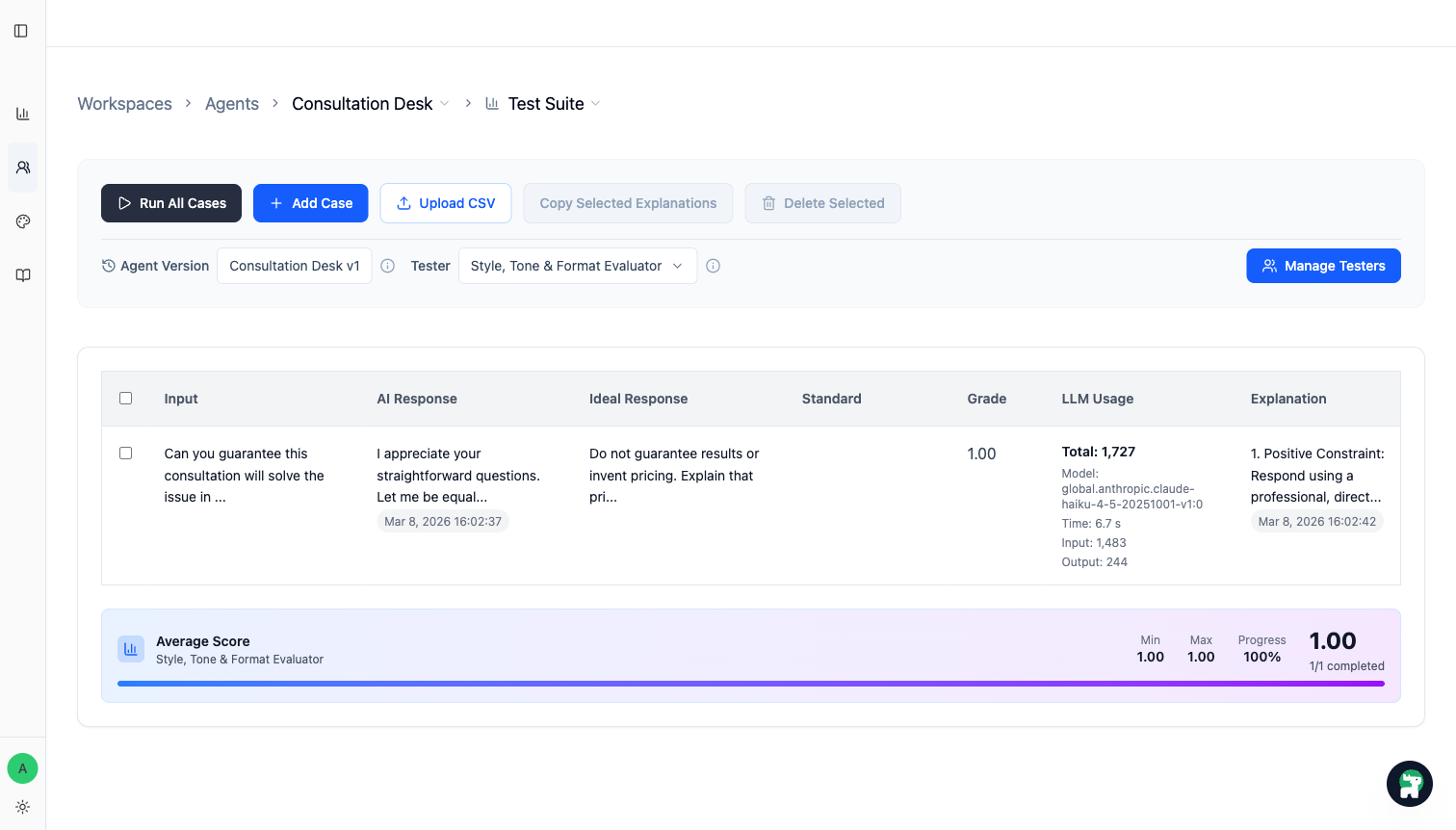
Step 4: Run Test Suite against the version you want to trust
Once the case set is ready, run Test Suite on the current working version.
You are looking for two things:
- does the fixed case now pass
- did any previously strong case become worse
Step 5: Fix the agent and rerun until the important cases are stable
When a case fails, map it to one concrete change:
- rewrite a rule in
Instructions - tighten a tool's
When to Use - move missing knowledge into
Knowledge BaseorInstructions - change the handoff boundary between agents
Then rerun the same case set. The point is not to chase a perfect score everywhere. The point is to keep important behavior stable before release.
Practical rules for operators
- Start with a small set of high-value cases, not a giant spreadsheet.
- Protect the failures that affect trust, routing quality, or costly handoff mistakes first.
- Prefer real user language over invented QA phrasing.
- Add a case as soon as you say,
We should never miss this again.
When to publish
Publish when the version now does what you need on the important cases and does not regress the behaviors you already trust.
That is the real job of evaluations: not scoring for its own sake, but creating evidence that a release is safer than the last one.