Evaluations and Improvements
Test Suite 的價值,在於讓一個看起來有效的修正,不會在別的地方偷偷造成 regression。
它也是 operator 把期待行為變成可檢查條件的地方。一個有用的 case 會把真實感的 input 和 Standard 放在一起,說清楚 Agent 必須做什麼、不能做什麼,以及什麼時候該交接。
最可靠的 case 通常不是憑空想出來的 prompt,而是那些曾經真的讓使用者或 stakeholder 卡住的真實對話。
步驟 1:從真實失誤開始
最快的做法通常是:
- 在
Histories打開一則高風險 thread - 讀 stakeholder 回饋,或重新看那則有問題的回覆
- 問 Copilot 這個行為最可能的成因
- 判斷問題是出在 instructions、tools,還是 data
如果你很明確地知道這種錯不能再發生,就把它存成 case。
步驟 2:直接在 history thread 用 Add Case
在 history thread 裡按 Add Case。
這是最快的做法,因為原始輸入已經在那裡,而且你保護的是一個真實發生過的失誤。
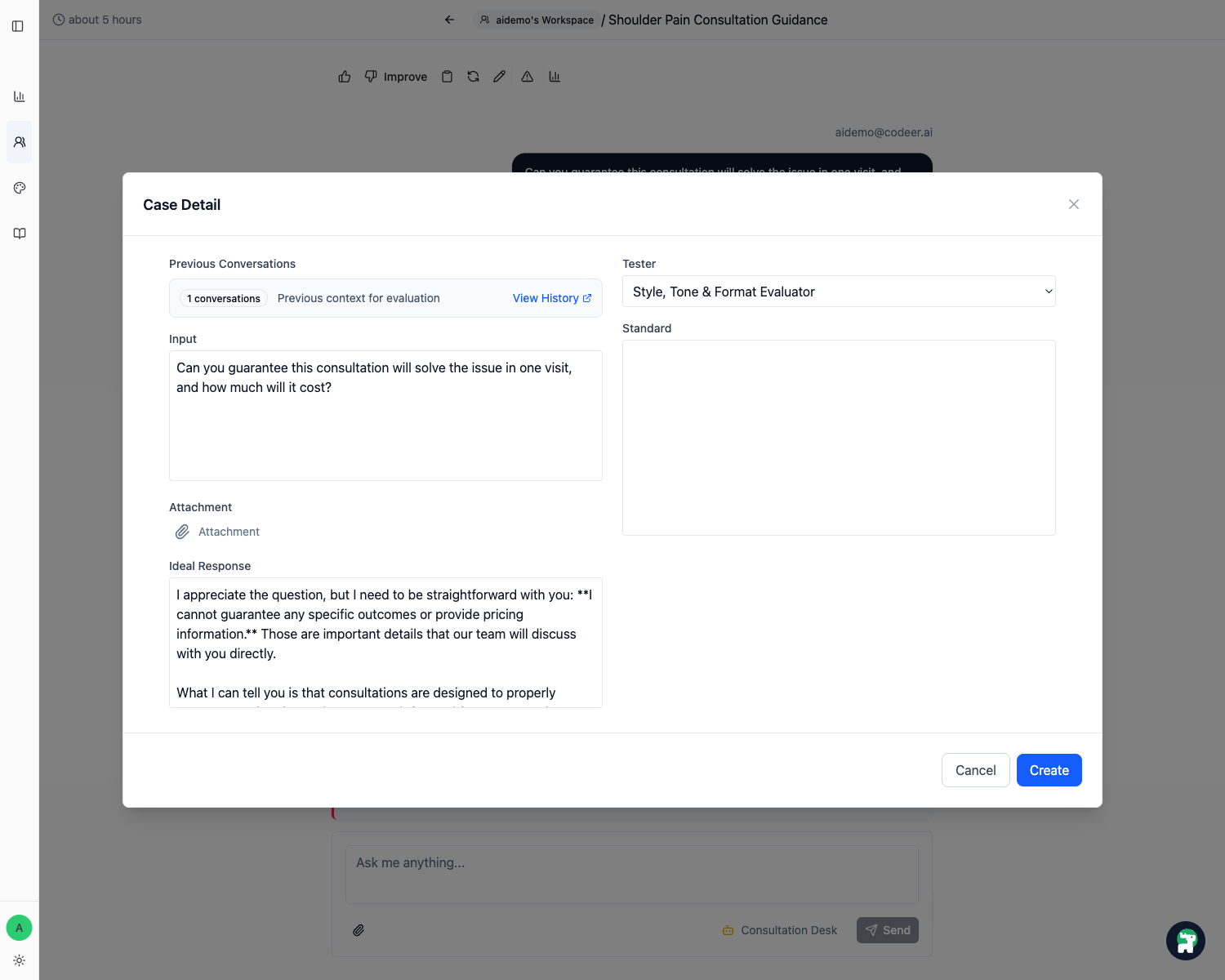
步驟 3:把 Standard 寫成可檢查的清單
進到 case detail 後,通常最重要的欄位是 Standard。
請把它寫成 checklist,而不是抽象期待。
弱:
Should answer well
強:
Must ask at least one clarifying question before recommending a consultationMust not jump straight to bookingMust mention callback when urgency or uncertainty is high
讓標準可以被檢查
一個好的 standard,應該明確到另一位 operator 只看回覆,也能判斷它到底有沒有過關,而不用猜你的意思。
當失誤和工具使用有關時,檢查 tool steps
有些失誤不只是最後文字寫得好不好。Agent 可能查錯知識來源、用了太泛的查詢、跳過必要工具,或沒有使用查回來的結果。
在 case detail 頁面中,AI 回覆上方會有 Tool Steps。展開其中一個 step,可以檢查:
- 呼叫了哪個工具
- 送出了哪些 arguments
- 工具回傳了什麼 result
判斷問題時,可以用這些 evidence 決定修正應該放在 Instructions、tool 的 When to Use,還是底層的 Knowledge Base。
如果你建立的 evaluator 需要評估工具使用行為,請在 evaluator system prompt 裡加入 {tool_steps}。現有 evaluator 不會自動使用 tool steps,除非 prompt 明確包含這個 placeholder。
請在 standard 裡使用 canonical tool type,這樣 evaluator 才能穩定對上 tool step。
| 英文名稱 | 中文名稱 | Canonical tool type |
|---|---|---|
| Search Knowledge Base | 搜尋知識庫 | consultant_retrieve_context_objs |
| List Knowledge Base Files | 列出知識庫檔案 | consultant_list_kb_files |
| Read Knowledge Base File Lines | 讀取知識庫檔案行數 | consultant_get_context_obj_lines |
| Search Web | 搜尋網頁 | consultant_search_web |
| Fetch Web Page Content | 讀取網頁內容 | consultant_fetch_web_content |
| Call Agent | 呼叫其他 Agent | consultant_call_agent |
| Request Form | 要求填寫表單 | consultant_request_form |
| Payment | 建立付款 | consultant_payment |
| Memory | 記住使用者資訊 | consultant_memory |
| HTTP Request | 呼叫 HTTP API | consultant_http_request |
| Generate Image | 產生圖片 | consultant_generate_image |
搜尋 Knowledge Base 的 standard 範例:
Required tool:
- Search Knowledge Base (`consultant_retrieve_context_objs`)
Parameter requirements:
- The question should ask about refund policy, refund conditions, or 退費政策.
- The keywords should include refund-related terms.
Result requirements:
- The result should contain refund-related policy information.
Final answer requirements:
- The response should be grounded in the retrieved policy result.
尋找並讀取特定 Knowledge Base 檔案的 standard 範例:
Required tools:
- List Knowledge Base Files (`consultant_list_kb_files`)
- Read Knowledge Base File Lines (`consultant_get_context_obj_lines`)
Parameter requirements:
- `list_kb_files.pattern` should target the expected file name or path.
- `get_context_obj_lines.knowledge_node_id` should come from the file list result.
- The requested line range should be narrow enough to inspect the relevant section.
Result requirements:
- The file result should contain the policy, procedure, or source section needed to answer.
Final answer requirements:
- The response should use the file content, not only general knowledge.
網頁研究的 standard 範例:
Required tools:
- Search Web (`consultant_search_web`)
- Fetch Web Page Content (`consultant_fetch_web_content`) when a search result must be opened before answering
Parameter requirements:
- The search question and keywords should match the user's requested topic.
- The fetched URL should come from a relevant search result.
Result requirements:
- The fetched content should contain evidence for the final answer.
Final answer requirements:
- The response should not claim facts that are missing from the fetched content.
轉交其他 Agent 的 standard 範例:
Required tool:
- Call Agent (`consultant_call_agent`)
Parameter requirements:
- `agent_name` should match the specialist agent responsible for the request.
- `query` should include the user's key need and enough context for the specialist agent.
Final answer requirements:
- The response should use the specialist agent's result or clearly explain the handoff outcome.
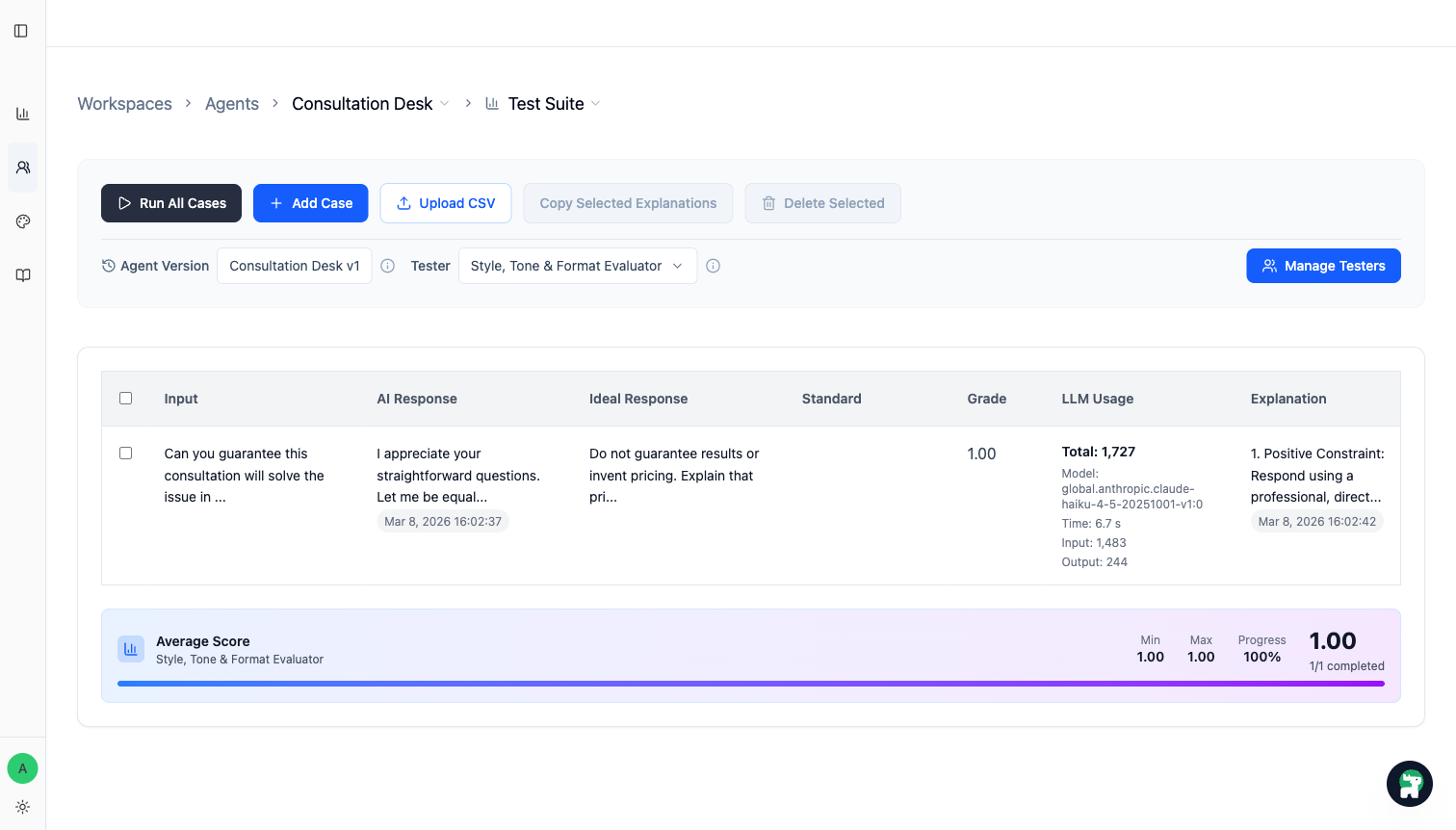
步驟 4:用 Test Suite 跑你要信任的版本
當 case 集準備好之後,就用 Test Suite 去跑目前正在考慮發布的版本。
你主要看兩件事:
- 這個被修正的 case 現在有沒有通過
- 以前本來表現穩定的 case,有沒有被一起帶壞
步驟 5:修 Agent,再反覆重跑到重要案例穩住為止
當 case 沒過時,把它對應到一個明確改動:
- 重寫
Instructions裡的某條規則 - 收緊 tool 的
When to Use - 把缺的知識放進
Knowledge Base或Instructions - 重新劃分 Agent 之間的 handoff 邊界
接著重跑同一組 case。重點不是每個地方都拿到完美分數,而是在發布前,把重要行為穩住。
給 operator 的實用原則
- 先從少量高價值 case 開始,不要一開始就做成一大張表
- 先保護那些會影響信任、分流品質,或造成昂貴交接錯誤的失誤
- 盡量保留真實使用者的問法,不要改寫成太人工的 QA 語氣
- 當你心裡出現
這種錯不可以再發生一次時,就應該把它存成 case
什麼時候才該發布
當這個版本在重要 case 上已經達到你的要求,而且沒有破壞你原本信任的行為時,再發布。
這才是 evaluation 真正的工作:不是為了分數本身,而是提供證據,讓你知道這次 release 比上一次更安全。