Evaluations and Improvements
Test Suite の役割は、良さそうに見える修正が別の場所で静かな regression を起こしていないかを止めることです。
同時に、期待する behavior を確認可能にする場所でもあります。役に立つ case は、現実的な input と、Agent が何をすべきか、何をしてはいけないか、いつ handoff すべきかを示す Standard を組み合わせます。
operator にとって最も強い case は、作り物の prompt ではなく、実際に user や stakeholder にとって重要だった会話から生まれます。
Step 1: 実際の失敗から始める
最短ルートは次の通りです。
Historiesで risky な thread を開く- stakeholder feedback または問題の返信を読む
- Copilot に原因を聞く
- 問題が instructions、tools、data のどこにあるか判断する
二度と逃したくない失敗だと分かったら、case に保存します。
Step 2: history thread から Add Case を使う
history thread で Add Case を押します。
これが速いのは、元の入力がそのままあり、守りたい失敗がすでに明確だからです。
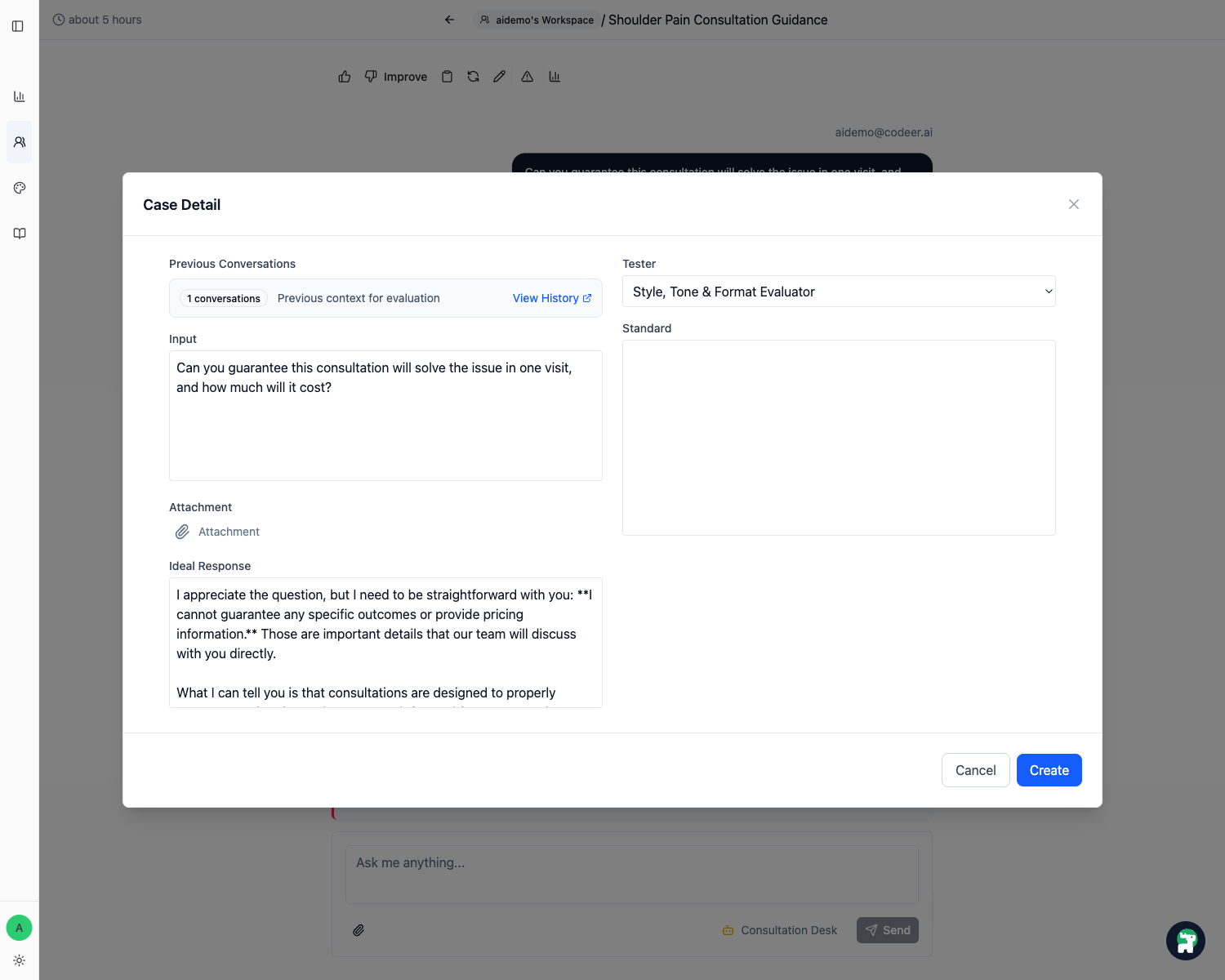
Step 3: Standard を checklist として書く
case detail では Standard が特に重要です。
曖昧な理想ではなく、確認可能な checklist にしてください。
弱い例:
Should answer well
強い例:
Must ask at least one clarifying question before recommending a consultationMust not jump straight to bookingMust mention callback when urgency or uncertainty is high
判断できる standard にする
良い standard は、別の operator が返信を読んでも、何をもって pass かを推測せず判断できるものです。
tool の使い方が失敗原因なら tool steps を確認する
失敗は最終的な文章だけが原因とは限りません。Agent が間違った Knowledge Base を検索した、query が弱すぎた、必要な tool を使わなかった、取得した result を無視した、ということもあります。
case detail では、AI response の上に Tool Steps が表示されます。step を展開すると、次を確認できます。
- どの tool が呼ばれたか
- どの arguments が送られたか
- どの result が返ったか
この evidence を使って、修正すべき場所が Instructions、tool の When to Use、または元の Knowledge Base なのかを判断します。
tool behavior を評価する evaluator を作る場合は、evaluator system prompt に {tool_steps} を含めてください。既存の evaluator は、この placeholder が明示されていない限り tool steps を使いません。
standard には canonical tool type を入れると、evaluator が tool step と安定して照合できます。
| English name | 中文名稱 | Canonical tool type |
|---|---|---|
| Search Knowledge Base | 搜尋知識庫 | consultant_retrieve_context_objs |
| List Knowledge Base Files | 列出知識庫檔案 | consultant_list_kb_files |
| Read Knowledge Base File Lines | 讀取知識庫檔案行數 | consultant_get_context_obj_lines |
| Search Web | 搜尋網頁 | consultant_search_web |
| Fetch Web Page Content | 讀取網頁內容 | consultant_fetch_web_content |
| Call Agent | 呼叫其他 Agent | consultant_call_agent |
| Request Form | 要求填寫表單 | consultant_request_form |
| Payment | 建立付款 | consultant_payment |
| Memory | 記住使用者資訊 | consultant_memory |
| HTTP Request | 呼叫 HTTP API | consultant_http_request |
| Generate Image | 產生圖片 | consultant_generate_image |
Knowledge Base 検索用 standard の例:
Required tool:
- Search Knowledge Base (`consultant_retrieve_context_objs`)
Parameter requirements:
- The question should ask about refund policy, refund conditions, or 退費政策.
- The keywords should include refund-related terms.
Result requirements:
- The result should contain refund-related policy information.
Final answer requirements:
- The response should be grounded in the retrieved policy result.
特定の Knowledge Base file を見つけて読む standard の例:
Required tools:
- List Knowledge Base Files (`consultant_list_kb_files`)
- Read Knowledge Base File Lines (`consultant_get_context_obj_lines`)
Parameter requirements:
- `list_kb_files.pattern` should target the expected file name or path.
- `get_context_obj_lines.knowledge_node_id` should come from the file list result.
- The requested line range should be narrow enough to inspect the relevant section.
Result requirements:
- The file result should contain the policy, procedure, or source section needed to answer.
Final answer requirements:
- The response should use the file content, not only general knowledge.
Web research 用 standard の例:
Required tools:
- Search Web (`consultant_search_web`)
- Fetch Web Page Content (`consultant_fetch_web_content`) when a search result must be opened before answering
Parameter requirements:
- The search question and keywords should match the user's requested topic.
- The fetched URL should come from a relevant search result.
Result requirements:
- The fetched content should contain evidence for the final answer.
Final answer requirements:
- The response should not claim facts that are missing from the fetched content.
別の Agent に渡す standard の例:
Required tool:
- Call Agent (`consultant_call_agent`)
Parameter requirements:
- `agent_name` should match the specialist agent responsible for the request.
- `query` should include the user's key need and enough context for the specialist agent.
Final answer requirements:
- The response should use the specialist agent's result or clearly explain the handoff outcome.
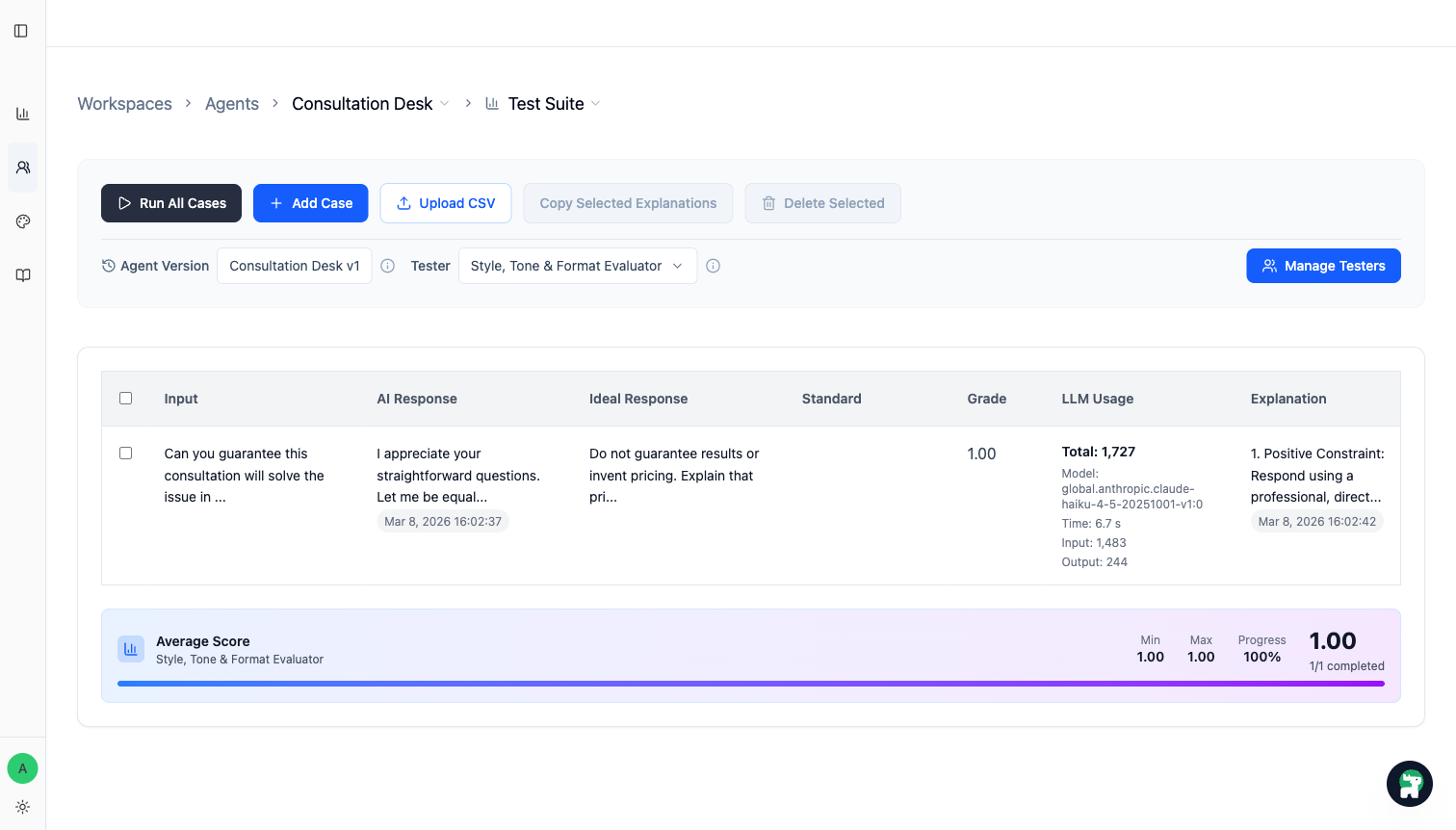
Step 4: 信頼したい version に対して Test Suite を走らせる
case が揃ったら、今の working version に対して Test Suite を実行します。
見るべきことは二つです。
- 修正した case が通るようになったか
- 以前強かった case が悪化していないか
Step 5: Agent を直して、重要 case が安定するまで回す
case が落ちたら、一つの具体的な変更に結びつけます。
Instructionsのルールを書き直す- tool の
When to Useを締める - 足りない知識を
Knowledge BaseやInstructionsに移す - Agent 間の handoff 境界を見直す
その上で同じ case set を再実行します。目的は全ケース満点ではなく、重要な挙動を release 前に安定させることです。
Operator 向けの実用ルール
- 最初は巨大な表ではなく、少数の高価値 case から始める
- trust、routing quality、高コストな handoff mistake に関わる失敗を先に守る
- QA 用に作った文より、実際の user language を優先する
これをもう二度と外したくないと思ったら、その場で case にする
Publish してよいタイミング
重要 case で必要な挙動が出ていて、すでに信頼している挙動を壊していないなら publish してよい段階です。
評価の本当の仕事は、点数のための点数ではなく、今回の release が前回より安全だと示す証拠を作ることです。